
MapReduce for dummies.
If you are a programmer or work in IT organisations. You must have heard the term “MapReduce” at some point. Some of you might be like myself, wondering what does it mean. It’s coined by very smart people from Google (reference). So, it must be good. Also, you must have heard this little project called “Hadoop” as an opensource for MapReduce. I have known it for a while but never get a full understanding of what it really means. People always mention that “Oh, you have a lot of data, MapReduce is very fast. Use that” but ever wonder why?
So, I would like to explain this to my blog as Einstein once said <a href=”http://www.brainyquote.com/quotes/quotes/a/alberteins383803.html#y5CAlRzOrI20wJPS.99”” title=”einstein quote”>“If you can’t explain it simply, you don’t understand it well enough”</a>.
If you like reading then this article is for you, written by Jeff and Sanjay from Google.
Here’s my version of what it means. MapReduce consists of two parts. Map and Reduce, Duh? I think the terms is a bit confusing if you don’t know what it means but I don’t know what to call it instead of this either. Let’s have a look at the first part Map.
Map really is like what we know in every language. Map<Key, Value> in Java. It has key and value. For example, if your country wants to run an election, you have four parties to choose from Party A, Party B, Party C and Party D. It’d be like this.
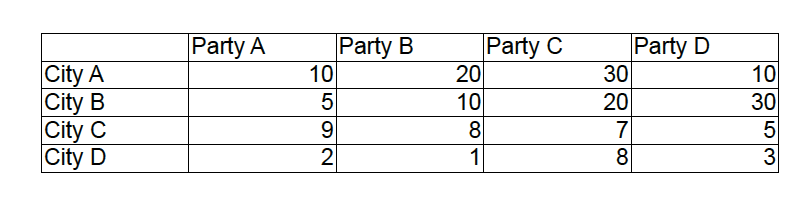
The key would be your party name. The value would be the votes for each of the key. So, this is how would you process in your computer. Let’s go back a little bit and have a look at raw data.
PartyA, 10
PartyA, 5
PartyA, 2
PartyB, 5
PartyB, 10
PartyB, 20
PartyB, 30
PartyC, 9
PartyC, 8
PartyC, 7
PartyC, 5
PartyD, 2
PartyD, 1
PartyD, 8
PartyD, 3
Then you would get something like this in Ruby. (If I show the code how I transformed this many ruby programmers might scream at me so you can do whatever you like to make it like that)
{"Party A"=>[10, 5, 9, 2]}
{"Party B"=>[5, 10, 20, 30]}
{"Party C"=>[9, 8, 7, 5]}
{"Party D"=>[2, 1, 8, 3]}
Now the part “Map” is done we can do the next part which is reduce. Reduce is where you process your data at your will on each key to get one or zero result. In this case we want to get the summation of the votes on each party. Luckily ruby comes with this already.
[10, 5, 9, 2].reduce(:+) # => 26
[5, 10, 20, 30].reduce(:+) # => 65
[9, 8, 7, 5].reduce(:+) # => 29
[2, 1, 8, 3].reduce(:+) # => 14
That’s it now we know that PartyB won the election.
So, here’s the important question. Why it’s fast?
Imagine, if in your country you have 100 cities and each city sends all the cards to the capital city to count, the process would be sequential and might be slow. So, we delegate that to each city then send the final result back to the capital city. That’s why you will hear a lot of people talking about “node”, “cluster” or “distributed” in MapReduce, because we delegate that to thousands of machines connected together. The classic example on the Internet right now is word counts which imagine how many documents or websites Google has to process each day.
That’s it. Any feedback is very welcome.
Reference:
http://www-01.ibm.com/software/data/infosphere/hadoop/mapreduce/
https://hadoop.apache.org/docs/r1.1.1/mapred_tutorial.html
http://www.onebigfluke.com/2013/01/why-is-map-reduce-faster-practical.html
http://stevekrenzel.com/finding-friends-with-mapreduce
Til next time,
noppanit
at 00:00
