
Lesson learnt from data cleansing. Part I
Lately, I have been experimenting on Kaggle competition. This is the one I chose because I want to use neo4j to give some recommendation or in a sense I want to do unsupervised learning. From day one I faced a lot of problem dealing with a lot of data and they are not clean in a way. For example, in this competition, there is users dataset which contains all the users. And there is a friend dataset which contains all the friends. The data look like this.
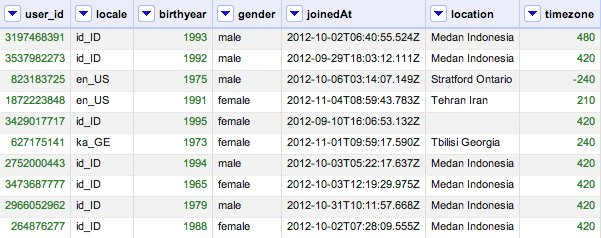
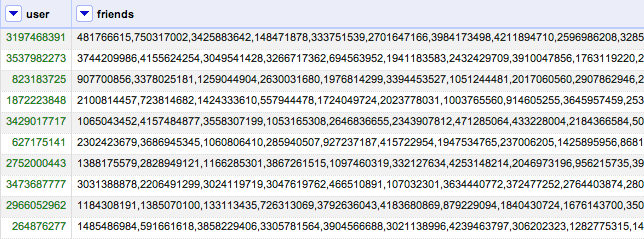
The first dataset I could dump everything into neo4j without any problem because it’s just 30000 records it only took me 5 mins to do it. However, the second dataset was kind of a problem because the column friends not all of the ids exist in users database which means the users don’t exist. So, I had to check if the ids exist in user dataset or not. It turned out that the friends dataset is quite large (about 50 MB) and it could be 3000 ids in one column. So, my first thought would be just to do it one by one.
Frist attempt
So, what I did first was to dump the whole users dataset to neo4j. And then for loop to check if id exists then insert if not just ignore it. I used cypher to check if the id exists. It turned out that I left my computer for 24 hours and it went just only 10% of the data. It was really slow. One thing from this was that I used neography which means it’s using REST api which usually it’s slower than embedded code. And I couldn’t wait for a whole week just to import the data. So, I moved on. The slow part was the checking every time so I guess it would be nice to clean the data before I dump that to neo4j.
Second attempt
I tried to use Google Refine to cross check two datasets but it couldn’t even pass the stage “split multi-valued cells” which to split column values to rows. Google Refine uses too much ram. I even tried to start EC2 instance but it froze along the way as well. I posted the question and got the solution here
Third attempt
I used MySQL to join the tables and and check if the ids exist. Dumping all the data to MySQL was pretty easy my plain old PHP and MySQL. It turned out the friends dataset got around 38 Million rows. And here’s the script I used to check if the id doesn’t exit spit it out and delete it.
SELECT uf.id, uf.friend_id, u.user_id FROM eventify.UserFriends uf LEFT JOIN eventify.Users u on uf.friend_id = u.user_id WHERE u.user_id is NULL LIMIT 1
It was also really slow since I just use my Macbook and didn’t even turn MySQL performance. So I moved on again.
Final attempt
I couldn’t believe that this will be the simplest and most effective way. What I did was to dump the whole users dataset to Hash in Ruby and check the friends dataset which surprisingly it only took Ruby 10 mins to do that. Then it only took Ruby and neo4j around 2 hours to import the cleaned data.
So lesson learnt for me was if anything can be done in memory do that first.
I’ll try to dump the rest in and blog about how did I get on with recommendation engine from neo4j.
Til next time,
noppanit
at 00:00
